Lab Report 5
Testing Two Implementations of MarkdownParse Using vimdiff With Many Test Files
This lab report contains the following:
- An explanation on how the different test results were found between both implementations of MarkdownParse.
- Links to two test files with different results between both implementations of MarkdownParse.
- For each test:
- A description of which implentation of MarkdownParse is correct (or incorrect, if both are) with its output.
- Actual outputs from both implementations of MarkdownParse.
- The expected output.
- For the (or for one) implementation that is incorrect:
- A short description of the bug found in the code that is causing the incorrect output.
- The location in the code where a change should be made that can correct the output.
Screenshots will be included in spoilers as to not take up uncessary space.
» This is a spoiler, Click Me!
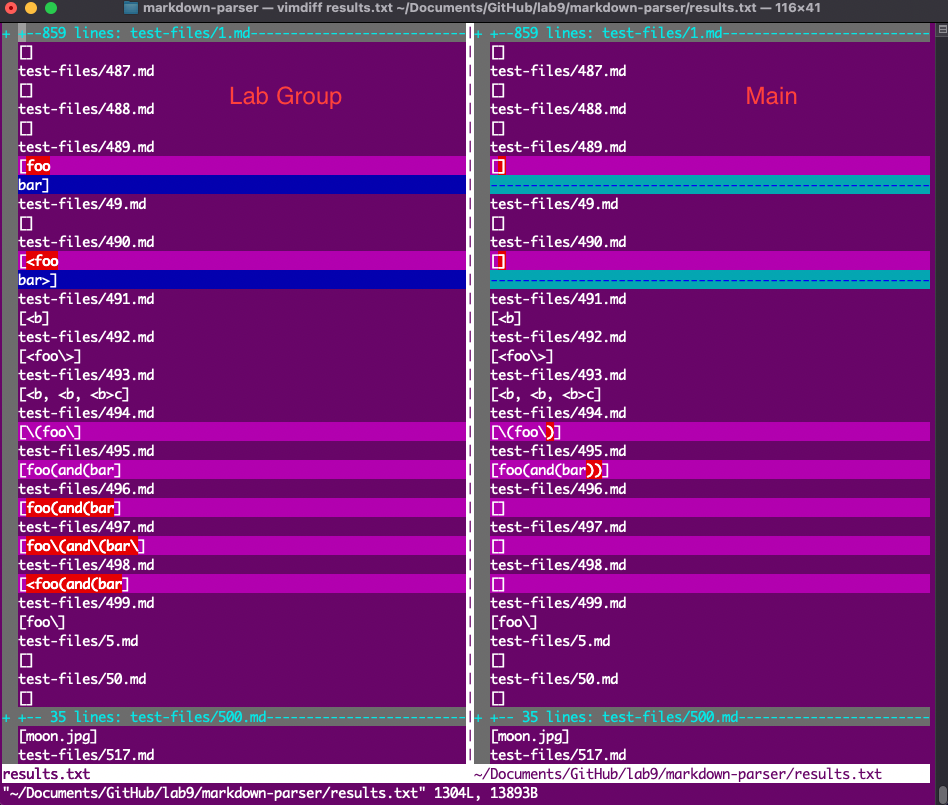
This is the inside of a spoiler where images will be located!To find the differences between the test results, I first used a script to run through all of the test files and output their results into a text file. I did this for both my lab group’s implementation of MarkdownParse as well as the main implementation of MarkdownParse given to the class. Next, I compared both text files and their results using the vimdiff command. Using this visual representation of the differences, I was able to select the two that I wanted to cover in this lab report; they are linked below.
» vimdiff
Test File 494
For this test file, neither implementation is correct. Screenshots have been provided for the actual outputs from both implementations. A screenshot and text has also been provided for the expected output.
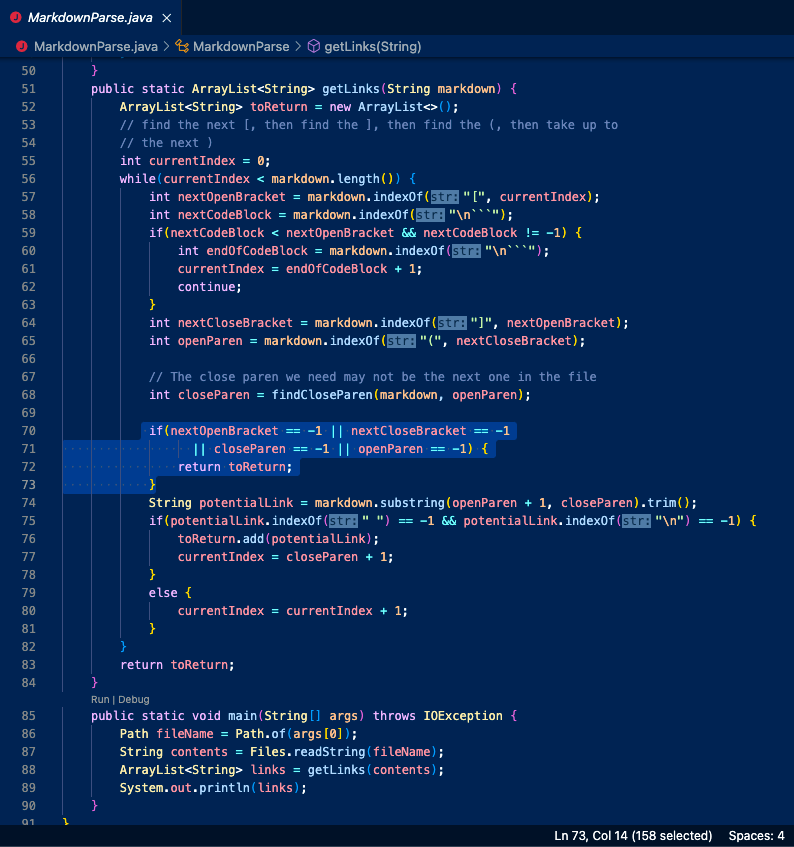
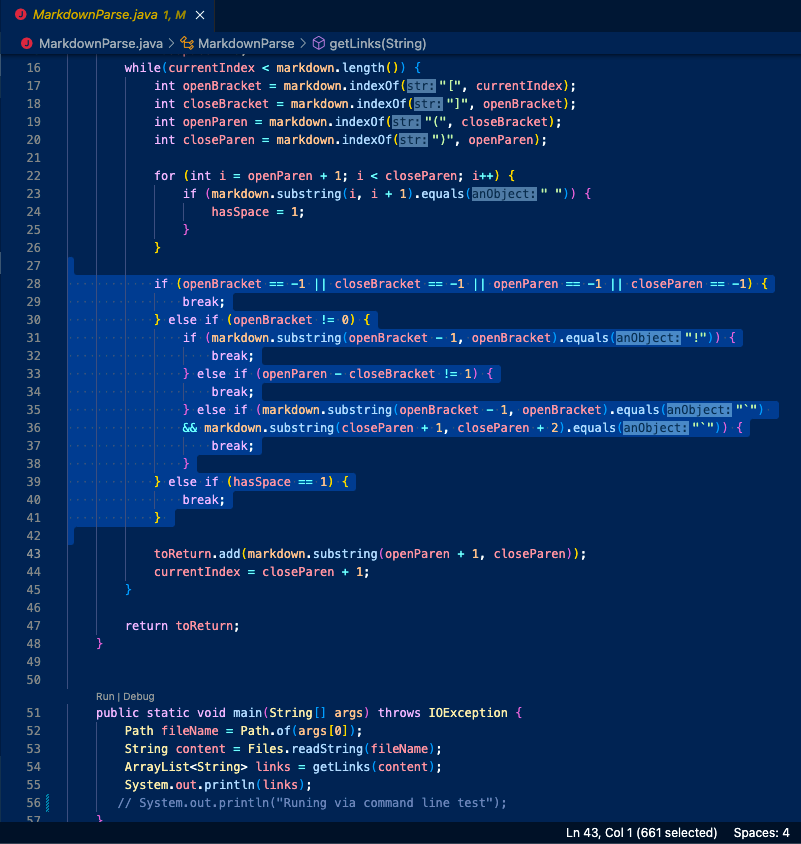
I will be going over my lab group’s implementation for this next portion of the report. My group’s MarkdownParse is going through the test file and deciding that everything that is in the parentheses is to be considered a URL, even the back-slashes (these should be omitted). It returns the contents as a URL once it reaches the first closing parenthesis, even though there is a nested pair in the actual syntax’s pair of parentheses. It should be only concluding that there is a URL once it reaches the closing parenthesis that completes the first open one. A screenshot of our MarkdownParse.java is also included below with a highlighted portion of code where a change needs to be made to produce the correct output. Somewhere in the highlighted portion, a check for back-slashes before parentheses should be added, changing the starting and ending position for where the URL is located. Some sort of counter also needs to be added, to ensure that the URL is only returned once the proper closing parenthesis has been reached.
» Lab Group's Actual Output

» Main MarkdownParse's Actual Output

» Expected Output
[(foo)]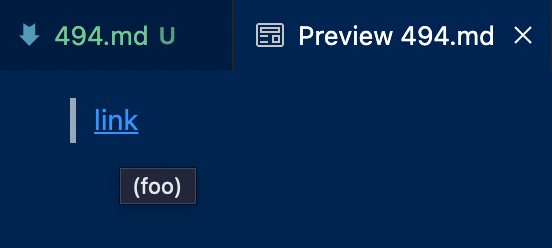
» Change Location in Code
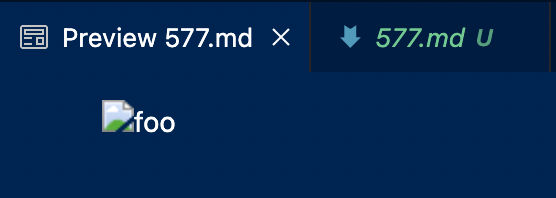
Test File 577
For this test file, my lab group’s implementation is correct. Screenshots have been provided for the actual outputs from both implementations. A screenshot and text has also been provided for the expected output.
I will be going over the main implementation for this next portion of the report. The MarkdownParse that was provided to the class is going through the test file and looking for an exact match to a URL syntax, even if it is actually an image syntax, for example. It returns the contents as a URL whether or not there is an exclamation point before the first opening bracket. It should be checking for the inclusion of an exclamation point before the first opening bracket, and if it finds one; not returning the URL as a valid link. It is important to ensure that this is only checked if the first opening bracket is not in the index of 0, or an out of bounds error will occur. A screenshot the main MarkdownParse.java is also included below with a highlighted portion of code where a change needs to be made to produce the correct output. Somewhere in the highlighted portion, a check for an exclamation point before the opening bracket should be added.
» Lab Group's Actual Output

» Main MarkdownParse's Actual Output

» Expected Output
[]
» Change Location in Code