Lab Report 4
Testing the Implementation of Two Versions of MarkdownParse
This lab report contains the following:
- A link to my lab group’s Markdown Parser repository.
- A link to another lab group’s Markdown Parser repository that my group reviewed.
- For three Markdown code snippets:
- Expected Output
- MarkdownParseTest Code
- Actual outputs for both implementations of MarkdownParse.
- Test results for both implementations of MarkdownParse.
- Potential code fixes to achieve expected output, if necessary.
Screenshots will be included in spoilers as to not take up uncessary space.
» This is a spoiler, Click Me!
This is the inside of a spoiler where images will be located!- My lab group’s Markdown Parser repository: Mashyuf/markdown-parser
- The reviewed Markdown Parser repository: cmy0357/markdown-parser
Snippet 1
For this snippet, both MarkdownParse implementations failed their tests. Both implementations included url.com when they should not have. I feel like this code change would be pretty small, less than 10 lines. The link should not have been included because since the backtick came first, it should parse as a code block. Of course, both implementations of MarkdownParse did not know this. The fix could be to check for a pair of backticks, with the first backtick occuring before the start of the URL syntax (before the opening bracket). My group’s implementation of MarkdownParse also did not output ucsd.edu, probably because of the closing bracket in the link title portion of the URL syntax. A fix for this could include skipping over brackets in the title portion if they do not complete a valid URL.
» Expected Output
[`google.com, google.com, ucsd.edu]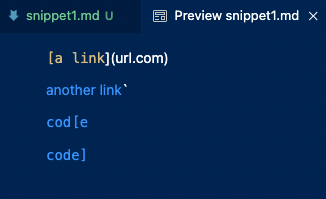
» Test Code

» Our Actual Output

» Our Failed Test

» Their Actual Output

» Their Failed Test

Snippet 2
For this snippet, both MarkdownParse implementations failed their tests. Both implementations outputted a.com(( instead of a.com(()). I feel like this code change may be longer than 10 lines. It looks like both implementations completed the URL early, because of the extra parentheses. A potential fix for this could be to have MarkdownParse count its current position in the parentheses to ensure that it returns the link once the syntax has actually completed. My group’s implementation of MarkdownParse also did not output example.com, probably because of the extra brackets. The fix for this could be similar to that of the previous failure’s solution; having the program count its current position in the brackets to ensure that it actually returns a link when one is present.
» Expected Output
[a.com, a.com(()), example.com]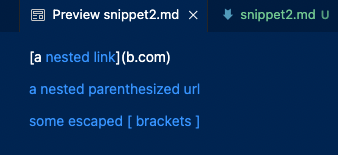
» Test Code

» Our Actual Output

» Our Failed Test

» Their Actual Output

» Their Failed Test

Snippet 3
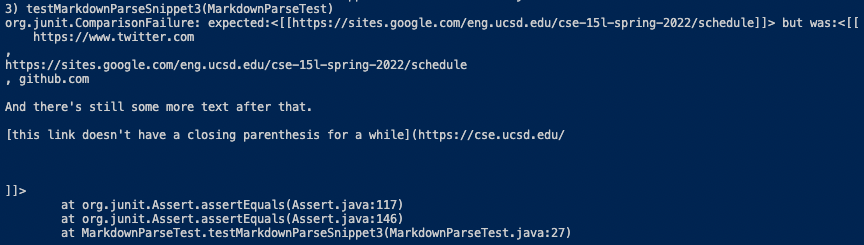
For this snippet, both MarkdownParse implementations failed their tests. The second URL is the only one that should have been outputted. The first and last contain line breaks in their syntax, and the second to last’s format is clearly incorrect. Unfortunately, my group’s implementation returned no links, and the other group’s returned three, with one combining another. Again, I feel like this code change may be longer than 10 lines. Like with the previous snippet, there could be a counter for the parentheses to ensure that only URLS with complete syntaxes are being returned (my group). This may be a smaller code change, but there could also be a check for line breaks in the link syntax to ensure that links with line breaks are not returned (other group).
» Expected Output
[https://sites.google.com/eng.ucsd.edu/cse-15l-spring-2022/schedule]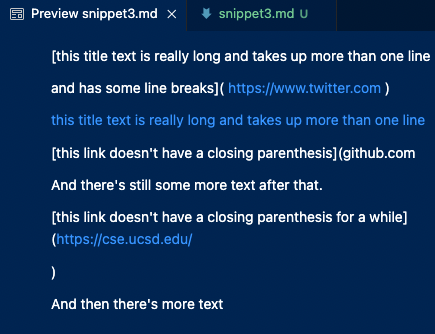
» Test Code

» Our Actual Output

» Our Failed Test

» Their Actual Output
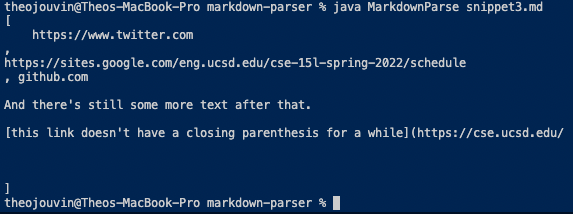
» Their Failed Test